
안녕하세요. AITRICS Research 팀입니다! 😊
최근 AITRICS 연구팀이 국제적인 인공지능 분야 내 가장 권위있는 학회로 꼽히는 ‘ICLR 2023’에서 주관하는 Trustworthy Machine Learning for Healthcare (TML4H) 워크숍에서 최고 논문상을 수상했습니다! 🥳🎉

이번 수상 받은 논문명은 Self-Supervised Predictive Coding with Multimodal Fusion for Patient Deterioration Prediction in Fine-grained Time Resolution으로, ‘이전보다 더 정밀한 환자 악화 예측 모델 개발’에 대한 내용입니다.
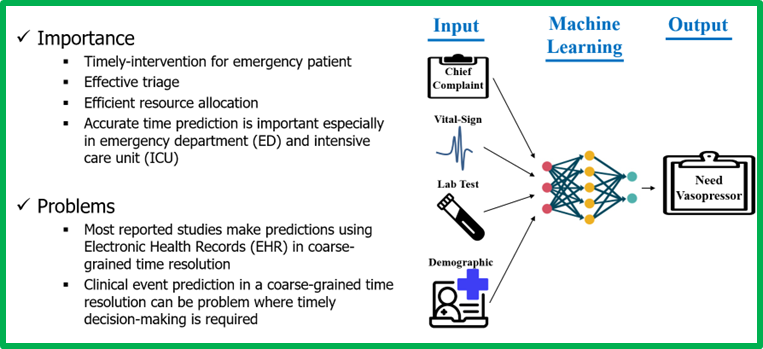
좀 더 자세히 말씀드리면, 저희는 해당 논문을 통해 환자의 전자건강기록(EHR)을 활용하여, 응급실과 중환자실에서 기존의 제품보다 좀 더 정밀한 환자의 상태 악화시간을 예측하는 모델을 제안했습니다. 📖🙂
이 모델은 단순히 환자의 과거 생체신호만으로 환자의 상태를 예측하는 것이 아니라, 예측을 위한 학습 과정에서 Self-Supervised Regularizer(자가 미래 감독학습)과 Multi-modal(멀티모달) 학습방식을 사용하여 성능을 향상시켰습니다.
또한, Fine-grained Time Resolution Prediction(세밀한 시간 해상도로의 예측) 방식을 통해 기존에는 미래 0~24시간 내 또는 0~48시간 내에 이벤트가(ex. 사망) 발생할지 아닐지를 예측했다면, 본 연구에서는 미래 0~1시간, 1~2시간, 2~3시간, ..., 11~12시간 동안의 발생여부를 전부 예측했습니다. (즉, 해상도가 24시간/48시간에서 1시간으로 세밀하게 됐다는 의미죠. 😎)
1. Multi-modal:
전자건강기록(EHR)에 환자의 데이터는 다양하게 존재합니다. (ex. X-ray 이미지, 혈액 검사, 주호소, 의사의 소견서, 간호사의 환자 기록, 바이탈 사인, 환자 개인 정보 등 🖥️📊)
이 다양한 데이터를 각각 Modality(모달리티)라고 부르며, 여러 개의 Modality를 사용할 때 Multi-modal(멀티모달)이라고
합니다. 이런 데이터들은 모두 환자의 상태를 보다 다양하게 나타내는데 도움을 줄 수 있습니다.
하지만 각 데이터는 모두 성질과 모양이 달라서 혼합하여(Fusion) 인공지능 모델에 사용하는데 문제가 있습니다.
본 논문은 다음과 같은 세가지의 혼합(Fusion) 방식을 사용하여 1) Multimodal Bottleneck Transformer¹ 2) Multimodal-Transformer¹ 3) Cross-Modal Attention Transformer² 환자의 생체신호(Vital-Sign, Lab-TEST)와 주호소(Text Data)를 혼합하여 환자의 악화 예측 성능을 높이는 실험을 했습니다.

2. Self-supervision:
예컨대, 예측모델이 환자의 과거부터 현재까지의 생체신호 데이터만 가지고 “미래 상태 악화”를 예측한다고 할 때, 저희는 더 나아가 만일 예측모델이 “미래 악화”뿐만 아니라 “미래 생체신호”가 어떻게 변화될지도 예측할 수 있다면 “미래 악화”도 더 잘 예측하지 않을까 생각했습니다.
때문에 아래처럼 Self-Supervised Regularizer(자가 미래 감독학습)으로 모델이 환자의 “미래 악화”와 환자의 “미래 생체신호”를 동시에 예측하게 하여 학습하여 예측 성능을 높이는 연구를 진행했습니다.

이 방법들은 AI(인공지능) 기술을 보다 효율적으로 활용하여 환자의 상태를 정밀하게 이해하고 적시에 대응할 수 있게
했습니다.
저희는 환자의 과거 생체신호만을 통해 아래와 같이 환자의 미래 “사망”, “바소프레신 사용”을 미래 0~1시 사이, 1~2시 사이, … 11~12시 사이에 일어날지 혹은 일어나지 않을지를 예측할 때, 당연하게도 먼 미래를 예측할 때 모델의 성능이 떨어지는 것을 확인했습니다. (빨간색 그래프)
여기서 추가로 환자의 주호소 Text 데이터가 혼합(Fusion) 됐을 때, 가까운 미래 예측 성능은 그대로 지만, 먼 미래 예측
성능이 올라갔습니다. (초록색 그래프)
저희는 이 현상의 이유를 Text 데이터는 “Slow feature”³의 성격을 가지고 있어서 좀 더 다이나믹(Dynamic)하게 바뀌는 생체신호보다 오래 유지되는 정보를 가지고 있어서 먼 미래 예측 성능을 올려준다고 가정했습니다.
또한 추가로 다양한 Self-supervision 학습을 진행하여 예측모델이 “미래 악화”뿐만 아니라 “미래 생체신호”가 어떻게
변화될지도 예측할 수 있게 했습니다. (파란색 & 검은색 그래프) 이때 먼 미래 예측 성능이 더 향상되는 것을 확인했습니다.

결론적으로 이 모델은 환자의 악화를 1시간마다 예측함으로써, 응급 상황에서의 신속한 의사결정과 효율적인 의료 자원 배분에 기여할 수 있게됩니다.
이와 같은 성과를 통해 AITRICS는 의료 분야에서의 인공지능 활용을 선도하고, 환자들에게 더 나은 의료 서비스를 제공하는 데 기여할 것입니다. 앞으로도 AITRICS는 이러한 연구를 통해 의료 서비스의 질 향상에 지속적으로 노력하겠습니다.
긴 글 읽어 주셔서 감사합니다! 💪🏻😊
논문 원문 보러가기 >> https://bit.ly/3I6B8Ti
References
1. Nagrani, Arsha, et al. "Attention bottlenecks for multimodal fusion." Advances in Neural Information Processing Systems 34 (2021): 14200-14213.
2. Tsai, Yao-Hung Hubert, et al. "Multimodal transformer for unaligned multimodal language sequences." Proceedings of the conference. Association for Computational Linguistics. Meeting. Vol. 2019. NIH Public Access, 2019.
3. Oord, Aaron van den, Yazhe Li, and Oriol Vinyals. "Representation learning with contrastive predictive coding." arXiv preprint arXiv:1807.03748 (2018).
'인사이트' 카테고리의 다른 글
| AITRICS, 미국에 떴다! (0) | 2023.06.02 |
|---|---|
| [규제 Insight] FDA PCCP Guidance 분석 (0) | 2023.05.30 |
| 의료인공지능 모델 개발 파이프라인 툴 소개: Clairvoyance (0) | 2023.05.23 |
| EHR 데이터를 활용한 의료인공지능 모델 개발 파이프라인 (0) | 2023.05.23 |
| 해석가능한 의료 인공지능 모델 (0) | 2023.05.23 |
